AI Execution Capacity System for Freelancers
A system-first framework to manage workload, prevent burnout, and stabilize output under irregular freelance work cycles using structured execution capacity control.
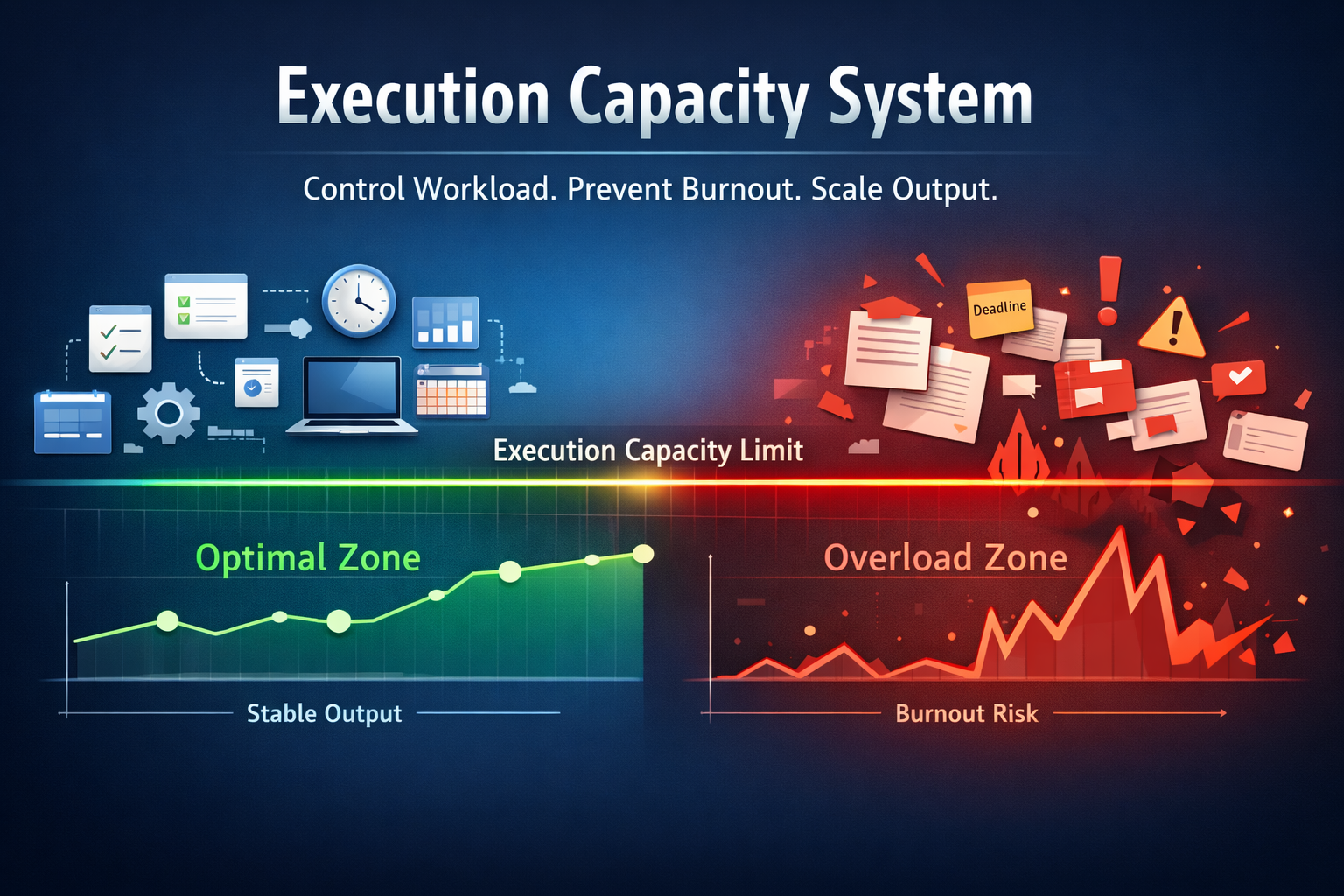
This system replaces reactive workload management with defined capacity limits, throughput control, and stability-driven execution rules.
Overview
An execution capacity system is the foundational layer that stabilizes output under irregular freelance workloads. Unlike traditional productivity methods that focus on doing more, this system defines how much work can be executed sustainably without triggering burnout, inconsistency, or performance degradation.
Freelancers do not fail because they lack discipline or motivation. They fail because workload is not aligned with capacity. When output exceeds sustainable limits, performance drops, recovery time increases, and income stability is disrupted. This creates a cycle where overwork is followed by underperformance.
The AI Execution Capacity System replaces reactive workload management with structured control. It defines capacity boundaries, regulates throughput, and ensures that execution remains consistent across varying work cycles. Instead of maximizing effort, the system optimizes stability.
This system operates as part of the broader FM Mastery architecture, connecting execution control with financial and operational systems. Capacity stability supports income consistency, reduces burnout risk, and enables long-term scalability.
To understand how execution systems connect with tools and workflows, explore the AI Tools Hub and the AI Productivity Tools for Freelancers ecosystem.
Table of Contents
- Overview
- Execution Capacity Definition
- Throughput vs Burn
- Load Saturation Signals
- Non-Recoverable Load
- Stability Framework
- Prioritization Framework
- AI Role
- Risk Control
- Decision Boundaries
- Scenario
- Implementation
- Failure Modes
- Integration with Productivity
- System Constraints
- Control Loops
- System Evolution
- Next Systems
Execution Capacity Definition
Execution capacity is the maximum amount of work that can be completed consistently without degrading performance, increasing recovery time, or triggering burnout. For freelancers, capacity is not fixed. It fluctuates based on workload intensity, cognitive demand, and external constraints such as deadlines and client expectations.
Traditional productivity models assume that output can be increased by extending working hours or increasing effort. This assumption ignores the limits of sustained performance. When workload exceeds execution capacity, output quality declines, decision-making deteriorates, and recovery periods become longer and less predictable.
Execution capacity is not a measure of how much work can be done in a single cycle. It is a measure of how much work can be sustained across multiple cycles without breakdown. This distinction separates short-term productivity from long-term stability.
Freelancers often operate without defined capacity limits. Work is accepted based on opportunity rather than sustainable throughput. This leads to periods of overextension followed by forced recovery, creating inconsistency in both output and income.
The AI Execution Capacity System defines capacity boundaries and enforces them through structured rules. Instead of reacting to workload pressure, the system regulates intake, controls execution pace, and maintains stability across all work cycles.
Capacity definition is the foundation of execution control. Without it, all subsequent systems—throughput management, risk control, and stability frameworks—operate without limits, increasing the probability of burnout and performance instability.
By defining execution capacity, freelancers shift from reactive workload management to controlled execution. This creates predictable output, reduces volatility, and supports long-term operational stability.
Defining Full Capacity: A Freelancer’s Capacity Profile

Execution Capacity Definition: What a Freelance System Can Sustain Repeatably establishes execution capacity as a system-level limit rather than a measure of potential, effort, or ambition. Within FM Mastery, execution capacity defines how much execution a freelance system can support repeatedly without degrading control, predictability, or structural stability. This definition separates sustainable execution from temporary endurance and anchors execution decisions in system limits rather than pressure or opportunity.
Why Execution Capacity Is Commonly Misread as Potential
In freelance environments, execution capacity is frequently conflated with potential. It is often interpreted as how much work could be done under ideal conditions, how far output might be pushed through effort, or how much opportunity appears available at a given moment.
This framing treats execution capacity as aspirational rather than structural. It assumes that if demand exists, energy is high, or results are temporarily positive, the freelance system must be capable of sustaining increased execution.
Within FM Mastery, this interpretation is structurally inaccurate. Potential describes what might be possible under pressure. Execution capacity describes what can be sustained without pressure.
Execution capacity is not inferred from ambition, opportunity, or short-term success signals. It is determined by system limits that remain in force regardless of circumstances.
What FM Mastery Means by Execution Capacity
Within FM Mastery, execution capacity is a finite system property.
It defines the maximum level of execution activity that a freelance system can sustain repeatably, without degradation of control, predictability, or stability. This limit exists independently of motivation, confidence, or perceived urgency.
Execution capacity is not:
• A target to be reached
• A reserve to be accessed temporarily
• A reflection of effort or commitment
Execution capacity functions as a load-bearing boundary at a specific point in system maturity.
Within Q5, execution capacity is treated as bounded and non-elastic. The system either operates within this boundary or exceeds it. No intermediate interpretation is permitted.
Execution Capacity vs Readiness, Effort, and Output
Execution readiness and execution capacity are related but distinct system conditions.
Execution readiness determines whether execution is permitted to begin without destabilization. Execution capacity determines how much execution can be sustained once it is permitted.
Effort and output operate downstream of both.
• Readiness answers whether execution is allowed
• Capacity answers how much execution can be sustained
• Effort answers how forcefully execution is applied
• Output reflects the visible result
High effort does not expand execution capacity.
High output does not confirm execution capacity.
A freelance system may be execution-ready while still possessing limited execution capacity. In such cases, execution is permitted but tightly bounded. Exceeding that boundary introduces structural strain regardless of competence or intent.
This distinction builds directly on the execution permission defined in Q5.1 — Execution Readiness Definition, and remains consistent with the control boundaries established in Q3 — Control & Predictability and the leverage limits formalized in Q4 — Leverage Readiness.
Why Exceeding Capacity Does Not Fail Immediately
When execution exceeds capacity, failure is rarely immediate.
Instead, the system compensates.
Control mechanisms absorb excess load temporarily. Predictability degrades gradually. Volatility increases incrementally rather than abruptly.
Because output may continue and visible breakdown may be delayed, over-capacity execution is often misinterpreted as sustainable performance.
Within FM Mastery, this delay is not treated as success. It is treated as lag between structural overload and observable consequence.
Capacity violations accumulate invisibly before they manifest operationally.
Execution Capacity as a Hard Governance Limit
Execution capacity functions as a hard governance limit, not a guideline.
It is enforced independently of:
• Short-term results
• External demand
• Personal urgency
• Perceived opportunity cost
Execution capacity does not negotiate with ambition. It does not respond to pressure. It does not expand in response to success.
Within Q5, execution capacity is defined to prevent freelance systems from being evaluated based on how much strain they can endure rather than how reliably they can function.
Execution that respects capacity preserves system integrity. Execution that exceeds capacity violates governance regardless of outcome.
How This Definition Constrains Execution in Later Phases
By defining execution capacity as a fixed, repeatability-bound system property, FM Mastery establishes enforceable constraints on future execution activity.
This definition enables later phases to:
• Distinguish permitted execution from excess execution
• Enforce limits without referencing motivation or discipline
• Block escalation based on output alone
• Preserve predictability as a non-negotiable condition
Execution capacity, as defined here, is not something to be tested. It is something to be respected.
Within FM Mastery, execution is constrained by what the system can sustain repeatedly, not by what it can survive temporarily.
Throughput vs Burn

Throughput vs burn is a structural distinction, not a performance judgment. In many execution systems, output is treated as evidence of health. Within FM Mastery Q5, that assumption is explicitly rejected.
Within Q5, throughput vs burn is used to classify whether execution output reflects sustainable system behavior or capacity violation.
This post defines the boundary between throughput and burn to prevent execution state from being misclassified based on surface-level results. High output can coexist with system failure. Low visible stress can coexist with capacity violation.
Without a formal boundary, execution governance loses the ability to detect degradation before it becomes irreversible.
Throughput as a System Property
Within Q5, throughput is the amount of execution output a system can sustain within its defined capacity without degrading stability, predictability, or reversibility.
Throughput is characterized by the following conditions:
• It is repeatable, not exceptional
• It is governed by system limits, not effort
• It remains stable across execution cycles
• It does not consume recovery margin
• It preserves reversibility
Throughput exists only when execution remains fully contained within the execution capacity defined in Q5.1 — Execution Capacity and fully utilized—but not violated—as defined in Q5.2 — Defining Full Capacity.
Throughput is not a target, goal, or aspiration. It is a descriptive system state that exists only while structural integrity is preserved.
Burn as a Capacity Violation State
Burn is execution that exceeds defined capacity and degrades system integrity, regardless of short-term output continuity.
Burn is not synonymous with fatigue, stress, or emotional exhaustion. In Q5, burn is a structural condition, not a subjective experience.
Burn is present when one or more of the following occur:
• Stability erodes under continued execution
• Recovery becomes dependent on compensatory effort
• Reversibility narrows or disappears
• Execution continuity is maintained by consuming future system capacity
In a burn state, output is no longer evidence of health. It becomes the mechanism through which degradation accumulates.
Why Burn Can Coexist With High Output
Execution systems can continue producing visible output after capacity has been violated. This occurs because structural degradation is not immediately observable.
Burn often remains undetected because:
• Output persists while internal slack is consumed
• Degradation accumulates before failure surfaces
• Reversibility loss lags behind throughput decline
• Structural strain does not immediately interrupt execution
As a result, systems operating in burn states may appear productive or stable until a triggering event exposes the accumulated damage.
Within Q5, this delay is treated as a governance risk, not an anomaly.
Sustainable Output as a Governance Condition
In Q5, sustainability is not a preference, value judgment, or optimization choice. It is a binary governance condition.
Output is classified as sustainable only if:
• It can be repeated without degrading system behavior
• It does not require future contraction to compensate
• It does not reduce the system’s ability to absorb disruption
If any of these conditions fail, output is classified as burn, regardless of volume, duration, or apparent success.
Sustainability is determined by structural continuity, not personal tolerance or visible endurance.
Throughput vs Burn Is a Boundary, Not a Spectrum
Q5 does not treat throughput and burn as points on a gradual scale. They are mutually exclusive system states.
• Execution within capacity produces throughput
• Execution beyond capacity produces burn
There is no intermediate classification. The presence of burn invalidates throughput, even if output remains unchanged.
This binary framing exists to prevent rationalization, delay, or reinterpretation of system health based on surface-level performance.
Relationship to Q5.1 and Q5.2
Q5.1 — Execution Capacity established execution capacity as a fixed system limit.
Q5.2 — Defining Full Capacity defined full capacity as capacity fully utilized but not violated.
Q5.7 clarifies what occurs after that boundary is crossed.
It does not redefine capacity.
It does not extend capacity.
It defines the structural consequence of exceeding it.
Bottom Line
Throughput is execution a system can sustain without structural damage.
Burn is execution that continues by consuming the system itself.
Q5.7 exists to ensure that output is never mistaken for health, and that execution governance remains anchored to capacity limits rather than visible performance.
Part of the FM Mastery framework.
View all Q5 — Execution Readiness & Capacity Governance posts
Related structural concept:
Throughput (systems definition)
Load Saturation Signals

Execution Saturation Signals and capacity exhaustion signals define observable, system-level states within FM Mastery. This document exists solely to make execution overload structurally visible before overt failure occurs.
This page does not prescribe responses, adjustments, containment actions, or corrective behavior.
It identifies signals only.
Execution saturation and capacity exhaustion are not experiences. They are system conditions that arise when execution load approaches or exceeds a fixed tolerance boundary already defined in Q5.5 — Execution Load Tolerance.
Execution Saturation — Pre-Exhaustion State
• Execution saturation is the condition in which the system operates at or near its maximum execution load tolerance while maintaining surface-level functionality.
• Saturation occurs before failure and before visible breakdown.
• At saturation, all available execution margin has been consumed.
A saturated system can continue producing output. Functionality persists because structural limits have not yet been catastrophically breached.
Saturation exists when the system has no remaining capacity to absorb additional execution load without degradation. The absence of immediate failure does not indicate safety. It indicates proximity to a boundary.
Capacity Exhaustion — Post-Tolerance State
• Capacity exhaustion is the condition in which execution load has exceeded the system’s defined tolerance.
• Exhaustion is not equivalent to stopping execution.
• Exhausted systems frequently continue to operate, but without structural integrity.
In exhaustion, the system is no longer governed by its original control rules. Output may persist, but predictability, containment, and sequencing integrity have already failed.
Exhaustion is defined by loss of control, not by cessation of activity. Continued execution after exhaustion conceals damage rather than preventing it.
Signal Categories — Structural Indicators Only
Execution saturation and capacity exhaustion are detected through system-level signal changes, not through subjective perception.
Control Signal Degradation
• Control signals lose clarity, consistency, or timing.
• Feedback loops that previously stabilized execution become delayed or distorted.
• The system’s ability to distinguish priority from noise weakens.
Control degradation indicates that governance layers are being consumed by load.
Decision Latency Changes
• Decision resolution time increases or becomes irregular.
• Decisions cluster, stall, or are deferred without structural cause.
• The system compensates by batching or bypassing decision points.
Latency shifts signal saturation even when output volume remains unchanged.
Boundary Enforcement Failure
• Previously enforced limits begin to blur or collapse.
• Constraints are violated implicitly rather than explicitly removed.
• Execution spills across defined system boundaries.
Boundary erosion indicates tolerance breach, not flexibility.
Sequencing Instability
• Execution order becomes inconsistent or reversible.
• Dependencies are bypassed or reordered under pressure.
• The system prioritizes immediacy over structure.
Sequencing instability is a late-stage saturation signal and an early exhaustion signal.
Silent Versus Visible Signals
• Silent signals emerge while the system still appears functional.
• They are structural shifts, not observable failures.
• Silent signals dominate during saturation.
Because output continues, silent signals are frequently misinterpreted as normal variance. This misinterpretation is structural, not perceptual.
• Visible signals emerge only after tolerance has been exceeded.
• They represent downstream effects, not root conditions.
• Visible failure is lagging evidence.
Waiting for visible signals guarantees that exhaustion is already underway. By that point, damage has already propagated through the system.
Irreversibility Window
• Saturation is time-sensitive.
• Prolonged saturation converts into capacity exhaustion without a discrete transition point.
The longer a system operates at saturation, the higher the probability that tolerance will be breached silently. Once exhaustion begins, recovery cost increases non-linearly.
Irreversibility is not defined by severity of response. It is defined by timing of recognition.
Late recognition converts manageable load proximity into structural exhaustion. This conversion occurs regardless of execution skill, intent, or awareness.
Governance Position
Execution saturation and capacity exhaustion are diagnostic system states. They do not imply action, intervention, or correction within this document.
Their sole function is to make invisible overload legible at the system level.
Forward dependency: Formal response logic to these signals is defined exclusively in Q5.7 — Pause, Throttle, and Containment Rules. No execution response is authorized prior to that definition.
Reference context: This governance framing aligns with established principles in general systems theory, used here solely for conceptual grounding.
Non-Recoverable Load
Non-Recoverable Load: When Freelance Systems Lose Reversibility defines a system condition in which execution load decisions permanently alter a freelance system’s structure, eliminating its ability to return to a prior operating state. Within FM Mastery, non-recoverable load is treated not as extreme pressure or temporary overload, but as a governance failure that results in the loss of reversibility as a protected system property.
Why Some Load Cannot Be Reversed
Within freelance systems, load is often assumed to be inherently reversible. The prevailing assumption is that if execution pressure is reduced, the system will naturally return to a previous operating state.
FM Mastery does not adopt this assumption.
Certain execution load decisions alter system structure rather than temporarily straining it. When structure is altered, reversibility is no longer guaranteed. Reducing load after the fact does not restore prior conditions because the constraints governing the system have changed.
Non-recoverability is therefore not a function of how intense load becomes, but of whether load decisions permanently modify system dependencies, coupling, or tolerance margins.
What FM Mastery Means by Non-Recoverable Load
Within FM Mastery, non-recoverable load is a system-level state.
It describes a condition in which execution decisions have permanently reduced the system’s ability to return to a previous operating configuration. The defining characteristic of non-recoverable load is the loss of reversibility.
Non-recoverable load is not:
• A period of high strain
• A temporary overload condition
• A reflection of effort, endurance, or intent
It is a structural outcome in which prior levels of optionality, slack, or decoupling no longer exist.
Once non-recoverable load is present, the system operates under a narrower and more rigid set of constraints, regardless of whether execution load is later reduced.
Reversible vs Non-Recoverable System States
FM Mastery distinguishes clearly between reversible strain and non-recoverable system change.
Reversible system states are characterized by:
• Temporary load-induced degradation
• Preservation of underlying system structure
• Restoration of prior behavior when load is removed
Non-recoverable system states are characterized by:
• Structural dependency changes
• Permanent reduction in tolerance margins
• Inability to return to previous operating modes
The distinction is not based on severity of load, but on whether the system’s configuration remains intact.
How Irreversibility Accumulates Without Collapse
Non-recoverable load rarely results from a single execution decision.
Instead, irreversibility accumulates incrementally through governance decisions that permit structural trade-offs without explicit recognition. Each decision may appear manageable in isolation, and the system may continue to function without visible failure.
Because collapse does not occur immediately:
• Structural loss is masked by continued output
• System narrowing is mistaken for efficiency
• Reduced optionality is not recognized as constraint
By the time load is reduced, the system’s former operating state may no longer be reachable.
This accumulation logic operates within the execution limits defined in Q5.2 — Execution Capacity Definition and follows the load-decision constraints established in Q5.3 — Load Governance for Freelancers.
Why Non-Recoverable Load Is a Governance Failure
Non-recoverable load is not classified as a performance issue.
It does not arise from insufficient effort, misjudged capability, or adverse conditions. It arises from governance decisions that allowed irreversible structural changes to occur without constraint.
Governance failure occurs when:
• Load decisions are evaluated only on outcomes
• Reversibility is not treated as a governing variable
• Structural consequences are deferred or ignored
This failure mode presumes execution permission has already been granted under Q5.1 — Execution Readiness Definition, but that load governance was insufficient to preserve reversibility.
What This Definition Prevents in Later Phases
By formally defining non-recoverable load, FM Mastery establishes a boundary that constrains future system behavior.
This definition prevents:
• Treating irreversible loss as temporary strain
• Assuming capacity can be restored by load reduction alone
• Misclassifying structural damage as recoverable variance
• Repeating governance failures under new conditions
This definition remains consistent with the control principles established in Q3 — Control & Predictability and the leverage boundaries formalized in Q4 — Leverage Readiness.
Within FM Mastery, non-recoverable load is recognized as a terminal change in system state, not a phase to be worked through.
Stability Framework
The stability framework defines how execution capacity is maintained across fluctuating workloads without triggering performance degradation or burnout. It operates as a control system that regulates workload intake, execution pace, and recovery cycles to ensure sustained output.
Without a stability framework, freelancers rely on reactive adjustments. Workload expands during high-demand periods and contracts during burnout phases, creating inconsistency in output and income. This reactive pattern prevents long-term system stability.
The framework introduces structured limits that align workload with execution capacity. Instead of maximizing throughput at all times, the system prioritizes consistent execution across cycles. This ensures that short-term output gains do not compromise long-term performance.
A core component of the framework is workload normalization. Incoming tasks are evaluated against capacity constraints before acceptance. This prevents overcommitment and maintains alignment between available capacity and required output.
Another component is recovery integration. Execution is not treated as a continuous activity but as a cycle that includes recovery periods. These recovery intervals restore capacity and prevent cumulative fatigue from escalating into saturation or collapse.
The framework also enforces execution pacing. Work is distributed across time to avoid spikes in intensity that exceed sustainable limits. By controlling pace, the system reduces variability in performance and maintains output consistency.
Stability is not achieved by reducing workload. It is achieved by aligning workload with capacity and maintaining that alignment through structured control. This transforms execution from a reactive process into a stable, repeatable system.
Prioritization Framework
The prioritization framework defines how work is selected, sequenced, and executed within the limits of execution capacity. Without structured prioritization, freelancers default to urgency-driven decisions, where immediate demands override capacity constraints and long-term stability.
Traditional prioritization focuses on importance or deadlines. While these factors are relevant, they do not account for execution capacity. High-priority work that exceeds capacity still creates overload, leading to performance degradation and delayed completion across all tasks.
The framework introduces capacity-aware prioritization. Tasks are evaluated not only by importance but by their impact on workload saturation and recovery cycles. This ensures that prioritization decisions align with sustainable execution rather than short-term urgency.
A key component is workload filtering. Incoming tasks are assessed against current capacity before being accepted. If capacity limits are reached, additional work is deferred, renegotiated, or declined. This prevents accumulation of unsustainable workload.
Another component is sequencing control. Tasks are ordered to balance cognitive demand and execution intensity. High-effort tasks are distributed to avoid clustering that leads to rapid capacity depletion.
The framework also enforces trade-off visibility. Accepting new work requires explicit evaluation of what must be delayed or removed. This eliminates the illusion that more work can be added without consequence.
Prioritization is not about doing more important work. It is about maintaining alignment between workload and capacity. When prioritization operates within system constraints, execution remains stable, predictable, and sustainable.
AI Role
AI operates as an execution support layer within the execution capacity system. It does not replace decision-making or override system constraints. Instead, it enhances visibility, enforces consistency, and reduces variability in workload management.
The primary function of AI is pattern detection. By analyzing workload intensity, task distribution, and execution timing, AI systems identify early signs of capacity strain. These signals enable proactive adjustments before saturation or burnout occurs.
AI also supports capacity forecasting. Instead of relying on assumptions about available time or energy, the system estimates realistic execution limits based on historical patterns. This improves alignment between planned workload and actual capacity.
Another function is execution monitoring. AI tracks deviations from system rules, such as overcommitment, task clustering, or reduced recovery intervals. These deviations are flagged to maintain adherence to defined constraints and control loops.
AI introduces decision support rather than decision automation. It provides insights and recommendations, but execution remains governed by system rules. This prevents over-reliance on tools and maintains structural integrity.
Automation is applied selectively. Repetitive processes such as task tracking, workload categorization, and performance monitoring are systematized to reduce cognitive load. This allows focus to remain on high-value execution activities.
The role of AI is not to increase output. It is to stabilize execution. By improving visibility, enforcing consistency, and reducing behavioral variability, AI strengthens the overall system without altering its foundational structure.
Risk Control
Risk control ensures that execution capacity is protected from overload, instability, and performance degradation. In a freelance environment, risk is not defined by external uncertainty alone but by the mismatch between workload and sustainable capacity.
The primary risk is capacity overshoot. When workload exceeds defined limits, execution quality declines, recovery periods increase, and output becomes inconsistent. This creates a cycle where short-term productivity gains lead to long-term instability.
Another critical risk is cumulative fatigue. Unlike immediate overload, cumulative fatigue develops gradually as recovery cycles are reduced or skipped. Over time, this leads to reduced cognitive performance, slower execution, and increased error rates.
Unstructured workload intake introduces additional risk. Accepting work without evaluating capacity constraints results in hidden overload. This risk is often delayed, becoming visible only when saturation signals emerge or deadlines begin to slip.
Risk control introduces boundaries that prevent these conditions from developing. Capacity limits, workload filters, and recovery requirements act as protective mechanisms. These controls ensure that execution remains within sustainable parameters.
Another function of risk control is early detection. By identifying patterns such as task clustering, reduced recovery intervals, and increasing execution time, the system can respond before instability escalates into burnout or performance collapse.
Risk control does not eliminate workload variability. It manages its impact. By maintaining execution within defined constraints, the system preserves stability, consistency, and long-term output sustainability.
Decision Boundaries
Decision boundaries define the limits within which execution decisions can be made without compromising system stability. In the absence of boundaries, freelancers rely on situational judgment, which introduces variability and increases the likelihood of overcommitment and capacity overshoot.
Boundaries operate as predefined rules that regulate workload acceptance, task sequencing, and execution intensity. These rules remove ambiguity by specifying what can and cannot be done within current capacity constraints. This prevents decisions from being influenced by urgency, opportunity, or short-term incentives.
A primary boundary is workload acceptance. New tasks are evaluated against available capacity before being committed. If capacity is exceeded, work must be deferred, renegotiated, or declined. This ensures that execution remains aligned with sustainable limits.
Another boundary is execution intensity. The system defines limits on how much high-effort work can be performed within a given cycle. This prevents clustering of cognitively demanding tasks that accelerate capacity depletion.
Time-based boundaries also play a critical role. Execution is constrained within defined working intervals, ensuring that recovery periods are preserved. Extending work beyond these limits may increase short-term output but reduces long-term capacity.
Decision boundaries also enforce trade-offs. Accepting additional work requires explicit removal or rescheduling of existing commitments. This eliminates the assumption that workload can expand without consequences.
Boundaries do not restrict growth. They enable sustainable execution. By defining clear limits, the system ensures that decisions support long-term stability rather than short-term gains that lead to burnout and inconsistency.
Scenario
Execution capacity systems are validated under real workload conditions rather than controlled environments. Freelancers operate across fluctuating demand cycles where workload intensity, deadlines, and cognitive requirements vary significantly. Scenario application demonstrates how the system maintains stability across these conditions without structural changes.
In a high-demand scenario, workload inflow increases rapidly due to client requests, deadlines, or new opportunities. Without system control, this leads to overcommitment and accelerated capacity depletion. Within the system, workload intake is filtered through defined capacity limits. Excess work is deferred or renegotiated, ensuring that execution remains stable.
In a low-demand scenario, workload decreases, creating available capacity. Instead of attempting to compensate through overextension or irregular effort, the system maintains consistent execution pacing. This prevents instability caused by sudden shifts in workload intensity and preserves long-term capacity.
In a fluctuating workload scenario, where demand alternates unpredictably between high and low periods, control loops ensure consistent execution behavior. Each workload change is processed through the same capacity rules, preventing reactive adjustments and reducing variability in output.
Unexpected disruptions, such as urgent deadlines or unplanned tasks, introduce additional pressure. The system absorbs these disruptions through predefined boundaries and prioritization rules rather than expanding workload beyond capacity. This prevents short-term pressure from destabilizing execution.
Multi-variable scenarios, where high workload, limited recovery time, and cognitive fatigue occur simultaneously, represent the most critical conditions. The system remains functional by enforcing constraints and maintaining execution within defined limits, preventing collapse into non-recoverable load.
The key principle across all scenarios is consistency without structural change. The system adapts execution within constraints rather than modifying its rules. This ensures that execution capacity remains stable regardless of external workload conditions.
Implementation
Implementation converts execution capacity from a conceptual framework into a repeatable operational process. For freelancers, implementation must function across variable workloads, ensuring that every task, decision, and commitment aligns with defined capacity limits.
The first step in implementation is capacity calibration. This involves identifying the sustainable level of output across work cycles, taking into account cognitive demand, task complexity, and recovery requirements. Capacity is not estimated once but refined through repeated execution cycles.
The second step is workload intake control. Incoming tasks are evaluated against current capacity before acceptance. This ensures that execution remains within limits and prevents overcommitment. Intake control acts as the first enforcement layer of the system.
The third step is execution structuring. Work is organized into defined sequences that balance intensity and recovery. High-effort tasks are distributed to avoid clustering, and execution pacing is maintained to prevent rapid capacity depletion.
The fourth step is constraint enforcement. Defined boundaries, such as maximum workload limits and mandatory recovery intervals, are applied consistently. These constraints ensure that execution remains stable regardless of workload fluctuations.
The fifth step is feedback integration. Each execution cycle is reviewed to identify deviations from capacity limits, workload clustering, or reduced recovery. These insights are used to refine calibration and improve future execution accuracy.
Implementation is not a setup process. It is a continuous execution loop. The system strengthens as consistency increases, reducing variability and stabilizing output across all workload conditions.
Failure Modes
Execution capacity systems do not fail due to lack of knowledge or intent. They fail when system rules are not applied consistently across workload cycles. Freelancers often understand capacity limits conceptually but override them under pressure, leading to breakdown in execution stability.
One of the most common failure modes is capacity override. Work is accepted beyond defined limits due to urgency, opportunity, or short-term incentives. This leads to immediate overload, reduced execution quality, and extended recovery periods that disrupt subsequent work cycles.
Another failure mode is workload clustering. High-intensity tasks are grouped within short timeframes, accelerating capacity depletion. Even when total workload appears manageable, poor distribution creates localized overload that impacts performance and increases fatigue.
Reactive adjustment is another source of failure. Instead of following predefined rules, execution behavior changes based on current workload conditions. This introduces variability, reduces predictability, and weakens the effectiveness of control loops.
Fragmentation of execution processes further contributes to failure. When workload intake, prioritization, and recovery are managed independently, decisions become disconnected. This lack of coordination results in conflicting actions that increase instability.
Over-reliance on motivation is another critical failure mode. Systems that depend on discipline rather than structured processes degrade over time. As cognitive load increases, consistency decreases, leading to gradual breakdown in execution.
The defining characteristic of failure modes is inconsistency in application rather than incorrect system design. When rules are enforced uniformly across all conditions, these failure modes are eliminated, and execution remains stable.
Integration with Productivity
Execution capacity systems do not replace productivity systems. They regulate them. While productivity focuses on task completion and efficiency, execution capacity defines how much work can be performed without destabilizing output. Without integration, productivity systems tend to push beyond sustainable limits.
Traditional productivity frameworks emphasize maximizing output through efficiency, speed, and optimization. However, these approaches often ignore capacity constraints. As a result, increased productivity can lead to faster saturation, higher fatigue, and reduced long-term performance.
The integration layer aligns productivity with capacity limits. Tasks are not only optimized for completion but also evaluated against execution capacity. This ensures that productivity improvements do not result in workload expansion beyond sustainable thresholds.
Task management systems operate within capacity boundaries. Instead of continuously adding tasks to increase output, workload is regulated to maintain balance between execution and recovery. This prevents productivity systems from becoming drivers of overload.
Time management also shifts under integration. Rather than maximizing hours worked, time is allocated based on capacity availability. High-effort work is scheduled within defined limits, and recovery intervals are preserved as part of the execution cycle.
Automation within productivity systems is applied selectively. Routine processes are optimized to reduce cognitive load, but execution intensity is not increased beyond capacity. This ensures that efficiency gains contribute to stability rather than overextension.
The integration of execution capacity with productivity transforms output from volume-driven to stability-driven. Productivity becomes a controlled component of the system, aligned with capacity constraints and long-term sustainability.
System Constraints
System constraints define the fixed limits within which execution capacity operates. These constraints ensure that all workload, decisions, and execution patterns remain aligned with sustainable output. Without clearly defined constraints, the system becomes flexible in ways that allow overload and instability to develop.
Unlike decision boundaries, which guide choices, constraints enforce non-negotiable limits. They establish the maximum workload, execution intensity, and recovery requirements that cannot be exceeded under any condition. This distinction ensures that flexibility does not compromise system stability.
A primary constraint is capacity ceiling. This defines the upper limit of work that can be executed within a given cycle. Exceeding this ceiling leads to immediate performance degradation and increased recovery time, making it a critical control point within the system.
Another constraint is recovery requirement. Execution cycles must include predefined recovery intervals to restore capacity. Skipping or reducing recovery introduces cumulative fatigue, which eventually leads to saturation and non-recoverable load conditions.
Time allocation constraints also play a key role. Execution is limited to defined working periods, preventing extension of work into recovery time. This ensures that capacity is preserved across cycles rather than depleted through continuous effort.
Constraint enforcement ensures that all system components operate within safe limits. Workload intake, prioritization, and execution must conform to these constraints, preventing localized decisions from destabilizing the overall system.
System constraints do not reduce output. They stabilize it. By maintaining execution within defined limits, the system produces consistent and sustainable results over time.
Control Loops
Control loops ensure that execution capacity is applied consistently across all workload cycles. In a freelance environment where workload fluctuates, control loops replace one-time decisions with repeatable processes that maintain alignment between workload and capacity.
At the core of control loops is sequence standardization. Each execution cycle follows a defined process: workload intake, capacity validation, task execution, and recovery integration. This structure ensures that every cycle operates under the same rules, eliminating variability caused by ad hoc decision-making.
Control loops also introduce continuous feedback. Each cycle generates data on workload distribution, execution intensity, and recovery adequacy. This feedback is used to identify deviations from system constraints and correct them in subsequent cycles, improving system accuracy over time.
Another function of control loops is behavioral stabilization. By enforcing the same process repeatedly, the system reduces reliance on motivation and discipline. Execution becomes rule-based rather than dependent on situational judgment, increasing consistency across varying workload conditions.
Control loops operate within defined constraints and decision boundaries. They do not override system rules but ensure that those rules are applied consistently. This alignment prevents localized decisions from disrupting overall system stability.
Over time, control loops reduce variability in execution outcomes. As processes are repeated and refined, workload distribution becomes more predictable, recovery becomes more effective, and output stabilizes across cycles.
Without control loops, execution systems degrade into isolated decisions. With control loops, execution becomes continuous, structured, and resilient under fluctuating workload conditions.
System Evolution
Execution capacity systems do not evolve through structural expansion or added complexity. They evolve through increased consistency, reduced variability, and improved alignment between workload and capacity. For freelancers, evolution is measured by stability across cycles rather than short-term increases in output.
In early stages, execution variability is high. Workload intake may exceed capacity, recovery may be inconsistent, and execution pacing may fluctuate. These deviations are not failures but indicators of misalignment between system rules and real-world application.
As the system is applied repeatedly, variability decreases. Workload is filtered more accurately, execution pacing stabilizes, and recovery becomes integrated into each cycle. This leads to more predictable output and reduced risk of saturation or burnout.
Evolution also occurs through improved calibration. Capacity limits become more precise as data from multiple cycles is incorporated. This allows for better forecasting of sustainable workload and more accurate decision-making within system constraints.
Another dimension of evolution is resilience. The system becomes capable of maintaining stability under increasingly complex workload conditions, including fluctuating demand, high-intensity tasks, and external disruptions. Stability is preserved without modifying core rules.
Importantly, evolution simplifies execution rather than complicating it. As consistency improves, fewer adjustments are required. Execution becomes more automated and less dependent on active decision-making, reducing cognitive load.
The outcome of system evolution is sustained performance. Work is executed consistently, recovery is preserved, and capacity remains stable across cycles. This transforms execution from a reactive process into a controlled and reliable system.
Next Systems
Execution capacity systems are not end points. They function as foundational layers that enable stability across all other operational and financial systems. Once execution is controlled and aligned with capacity, the system transitions from stabilization to expansion.
The first transition is toward income stability systems. With execution capacity defined and controlled, output becomes consistent, allowing freelancers to stabilize income patterns. This reduces volatility and creates predictable revenue cycles.
The second transition is toward financial control systems. Stable execution supports structured cashflow management, enabling better allocation, savings consistency, and reduced reliance on reactive financial decisions. Execution stability becomes the foundation of financial stability.
Another progression is toward scalability systems. With capacity limits clearly defined, freelancers can expand output strategically without triggering overload. Growth becomes controlled rather than reactive, ensuring that increased workload does not compromise system stability.
Operational systems also evolve as execution stabilizes. Decision-making becomes more structured, workload planning improves, and system integration strengthens. This reduces cognitive load and increases overall efficiency.
The final stage is system integration. Execution capacity, productivity, income, and financial systems operate as a unified structure. Each system supports the others, creating a stable and scalable operating environment.
The purpose of execution capacity control is not limitation. It is enablement. By stabilizing execution, the system creates the conditions required for sustainable growth, long-term performance, and operational resilience.
Related Systems & Next Steps
The AI Execution Capacity System operates as a foundational layer within the broader FM Mastery architecture. To fully stabilize your freelance operations, integrate this system with the following:
-
AI Tools Hub:
Explore the full ecosystem of tools that support execution, automation, and financial decision-making.
Explore AI Tools for Freelancers -
AI Productivity & Operations:
Learn how productivity systems integrate with execution capacity to maintain stable output.
AI Productivity Tools for Freelancers -
Income Stability Systems:
Understand how controlled execution leads to predictable income and reduced volatility.
AI-Smart Income Growth for Freelancers -
Money Management Systems:
Connect execution stability with structured financial control and cashflow management.
AI-Powered Money Management for Freelancers
Execution capacity is the bridge between productivity and financial stability. Once controlled, it enables consistent output, predictable income, and long-term system growth.